
Advanced Graphql - Subscription performance.
Problem Statement
For every broadcast, Subscription Query is executed once per each client. A large server performance would be dramatically impacted by this.
Graphql Subscriptions works as a listener to wait on server to push data instead of periodically polling the server. Besides Graphql subscriptions, there are many other existing solutions that can “listen” to server. Old fashioned websocket, ActionCable (Ruby on Rails), etc. One of the biggest difference between Graphql Subscription and others is that Graphql subscription subscript be one event, but the the payload can vary for each client. For example, image a subscription definition:
type UserStats{
recentLogin: Date
numPost:Int
}
type User{
id: Int
name: String
email: String
stats_id: Int # Foreign key to stats table
stats: UserStats
}
Subscription {
UserAdded: User
}
resolvers:
const resolvers ={
UserAdded:{
subscribe: ()=> new AsyncIterator();// following apollo server's subscription guide.
resolve:async (payload, args, ctx, info)=>{
// payload(payload is the data from broadcast)
const {id} = payload;
//run query and resolve the User using
return db.users.get(id);
}
}
}
Each client could subscribe to a subset of these fields and nested fields. Unlike regular pubsub + websocket framework, where the all clients receive the same broadcast message in a channel, in Graphql subscription, each client needs to call resolve to refetch the exact data when the broadcast happened. (see “Execute Subscription Query” below)
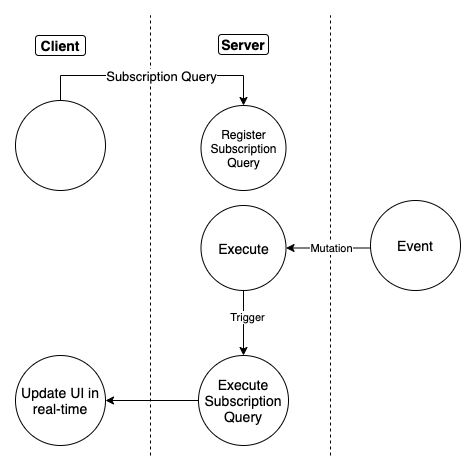 (credit:https://dgraph.io/blog/post/how-does-graphql-subscription/).
(credit:https://dgraph.io/blog/post/how-does-graphql-subscription/).
This immediately brings up a problem, for each broadcast, the resolve function is called N times, where N is the number of subscribed client. This has a significant impact as the number of subscription client increases.
Solution 1. Dataloader
Now, if you use some kind of dataloader mechanism that is globally available, then this may not be a big problem. Because even though the resolver is called N times, they maybe merged in one single dataloader and endup with only 1 database visit.
const pool = new dbPool() // PgPool or any database pool
// This must be exist for all resolver calls.
const userLoader = new DataLoader((ids)=>{
const client = await pool.connect();
const users = client.query(`select * from users where id in (${ids.join(",")})`); // not exactly good, but you get the idea.
// map users to result because users order may be different from ids.
const result = users // make sure order is correct.
return result;
});
// graphql resolve function
resolve: async (payload, args, ctx, info)=>{
const {id} = payload;
return userLoader.load(id);
}
Solution 2. Prisma
Or if you use prisma client, where prisma is globally availabe, and you programed the resolve function carefully, this problem may also go away.
More Problem: What if you use PostGraphile
One problem I have ran into in particular, is PostGraphile’s subscription.
If you don’t know about it yet, check it out here. Basically this library generate the a graphql schema from a postgreSQL schema, it use the index/foreign key to create assications, also it uses a “look ahead” to convert a large GraphQL query into a complex SQL query and run it once to retrieve all the data. It can also be directly invoked as a server with jwt, rbac etc.
Because of this feature, with PostGraphile, you don’t need to manually setup prisma client, datasources, or any kind of ORM for the resolvers.
PostGraphile’s subscription cleverly uses Postgres’s Pubsub (so you don’t need to run a redis) as the broker and uses the query function pg_notify as trigger to trigger subscriptions. see more information here.
One example of how you can set up subscription with PostGraphile is like following.
type UserAddedPayload{
user: User
# This is returned directly from the PostgreSQL subscription payload (JSON object)
event: String
}
extend type Subscription {
userAdded: UserAddedPayload @pgSubscription(topic: userAdded)
}
const resolvers = {
UserAddedPayload: {
user: async(event, args, ctx, info)=>{
const {graphile: {selectGraphQLResultFromTable}} = info;
const {id} = event;
const rows = await selectGraphQLResultFromTable(
sql.fragment`public.users`,// table name
(tableAlias, sqlBuilder)=>{
sqlBuilder.where(sql.fragment`${tableAlias}.id = ${sql.value(event.id)}`)
})
return rows[0]
}
}
}
The selectGraphQLResultFromTable embed the “look ahead” technique and construct a complex sql to retrieve the data. If a client subscribe to server:
subscription {
UserAdded:{
id
name
email
stats{
numPost
}
}
}
Inside the seleceGraphQLResultFromTable it would construct an SQL like this:
select id, name, email, to_json(select numPost from user_stats us where us.id = users.stats_id) from users where id = xx
The exact query will involve some alias and cte, but you get the idea.
However, this look ahead helps to retrieve data with 1 single query per client, but we still cannot resolve the problem that the resolver is called once for each client. So we still need N database visit per broadcast.
Solution for PostGraphile subscription.
The solution for this problem is to not use the dataloader “vertically”. Let me explain. DataLoader is used to batch request to a single request, and split up the result for each individual request. Like so
getUser(1)
getUser(2) = > DataLoader calls getUsers([1,2,3]) => split the response.
getUser(3)
Imagine this is a “horizontal way of batching”, there is also a “vertical” batching. Like so:
getUser(1, ["id","name"]) // get user id=1, but only "name", "id" field
getuser(1, ["id","email"]) // get user id=1, but only "name", "email" field
// batching by dataloader
DataLoader calls getUser(1, ["id","name","email"]) then split up the response.
In Graphql Document, the “fields” are stored in the info(4th parameter when calling resolver), access by info.fieldNodes[0] so we in pseudocode, we should do this:
const userVerticalDataLoader = new DataLoader((infos)=>{
// merge all infos into one large info that contains all fields.
const mergedNodes = merge(infos.map(i=>i.fieldNodes[0]));
const fullInfo = {...infos[0], fieldNodes:[mergedNodes]};
// call some magic function to resolve with this full Info
const fullResult = magicResolve(fullInfo);
// For each individual info, we just send back this full result, it returns more data than they ask for, but the extra data are not used.
return infos.map(info=> fullResult);
})
const resolvers = {
UserSubscriptionPayload:{
user: async(event, args, ctx, info)=>{
const result = userVerticalDataLoader.load(info)
return result;
}
}
}
The merge function is a recursive function that just manually merge all the selectionSet in a graphql Document. I wrote one myself and it works pretty well, but not guarantee to be bug free.
function isFieldNode(n: SelectionNode): n is FieldNode {
if ((n as FieldNode).name) return true;
return false;
}
/**
* @description Handles the Nodes of the query Node. The query is converted to an AST. Sometimes
* multiple queries to the same field can be merged to one to save trips to database. This function
* merges multiple query nodes into one (union) version of all requests and make one call to
* database. This is especially useful when broadcasting in pugsub
* @param {*} returnNodes
*/
export const merge= (returnNodes: FieldNode[]) => {
const setOfFields: AnyObject = {};
returnNodes.forEach((node) => {
if (node.selectionSet) {
const {
selectionSet: { selections },
} = node;
selections.forEach((selection) => {
if (isFieldNode(selection)) {
const {
name: { value },
selectionSet,
} = selection;
if (setOfFields[value]) {
// This field is already in the output, merge it if necessary
if (selectionSet) {
setOfFields[value] = merge([setOfFields[value], selection]);
} // Otherwise, leave it.
} else {
// This field is not in the output, put it in
setOfFields[value] = selection;
}
}
});
}
});
// Convert setOfFields to a fieldNode
const template = returnNodes[0];
const { selectionSet } = template;
const newSelectionSet: SelectionSetNode = {
...selectionSet,
selections: Object.values(setOfFields),
kind: 'SelectionSet',
};
return { ...template, selectionSet: newSelectionSet };
};
Now let’s talk about the magicResolve. it is pretty hard to figure out how PostGraphile does the look up or find a utility existing function to match our need. The exposed selectGraphQLResultFromTable hides all the secrets from the user. So instead of figuring all these out, I uses delegateToSchema from @graphql-tools/delegate, I basically construct a graphql query like below and execute the query with the schema.
useById(id: xx){
id
email
name
....
}
const magicResolve = async (fullInfo, id)=>{
return await delegateToSchema({
context,
info: fullInfo,
schema: schema,
operation: 'query',
fieldName: 'useById',
args: {id}
})
}
In practise, there are a lot of details to sort out, for example, where do these context, schema come from ? From our experiment, the PostGraphile context for query only needs a pgClient to function correctly, so we could just simply construct a context inside the dataloader. schema should be the same for all queries, so we could set the schema when we create these dataloaders. Or we just pick schema from any info.
For a full repo to demostrate this, check out this repo